
前言
之前我们有提到数据卷:emptydir ,是本地存储,pod 重启,数据就不存在了,需要对数据持久化存储
对于数据持久化存储【pod 重启,数据还存在】,有两种方式
- nfs:网络存储【通过一台服务器来存储】
步骤
持久化服务器上操作
- 找一台新的服务器 nfs 服务端,安装 nfs
- 设置挂载路径
使用命令安装 nfs
1 | yum install -y nfs-utils |
首先创建存放数据的目录
1 | mkdir -p /data/nfx |
设置挂载路径
1 | # 打开文件 |
执行完成后,即部署完我们的持久化服务器
Node 节点上操作
然后需要在 k8s 集群 node 节点上安装 nfs,这里需要在 node1 和 node2 节点上安装
1 | yum install -y nfs-utils |
执行完成后,会自动帮我们挂载上
启动 nfs 服务端
下面我们回到 nfs 服务端,启动我们的 nfs 服务
1 | systemctl start nfs |
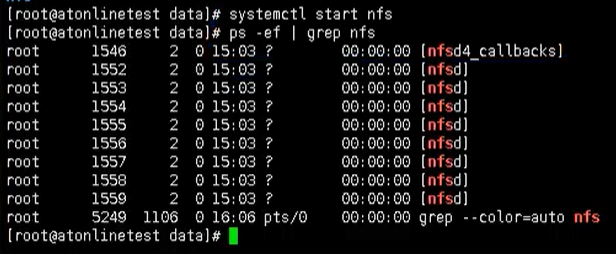
K8s 集群部署应用
最后我们在 k8s 集群上部署应用,使用 nfs 持久化存储
1 | # 创建一个pv文件 |
然后创建一个 yaml 文件 nfs-nginx.yaml
通过这个方式,就挂载到了刚刚我们的 nfs 数据节点下的 /data/nfs 目录
最后就变成了: /usr/share/nginx/html -> 192.168.44.134/data/nfs 内容是对应的
我们通过这个 yaml 文件,创建一个 pod
1 | kubectl apply -f nfs-nginx.yaml |
创建完成后,我们也可以查看日志
1 | kubectl describe pod nginx-dep1 |

可以看到,我们的 pod 已经成功创建出来了,同时下图也是出于 Running 状态
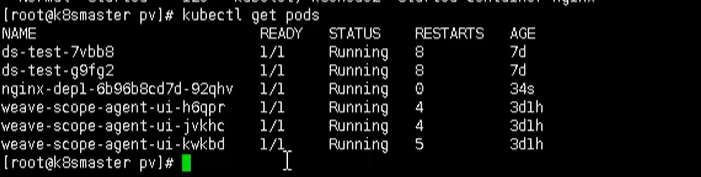
下面我们就可以进行测试了,比如现在 nfs 服务节点上添加数据,然后在看数据是否存在 pod 中
1 | # 进入pod中查看 |

PV 和 PVC
对于上述的方式,我们都知道,我们的 ip 和端口是直接放在我们的容器上的,这样管理起来可能不方便
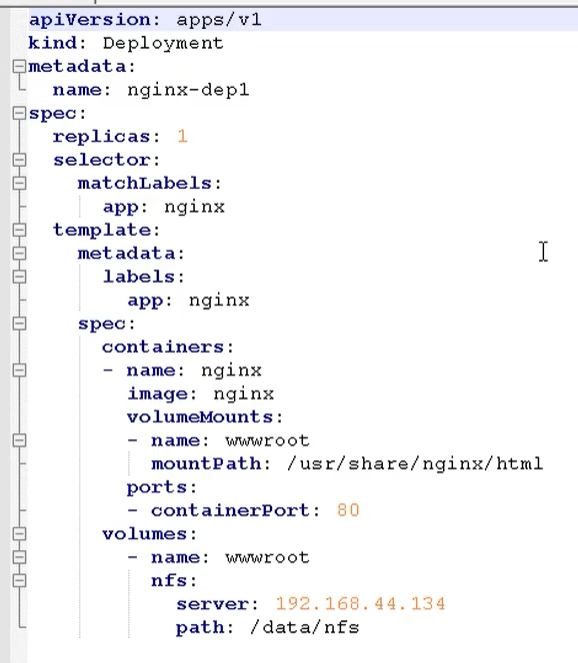
所以这里就需要用到 pv 和 pvc 的概念了,方便我们配置和管理我们的 ip 地址等元信息
PV:持久化存储,对存储的资源进行抽象,对外提供可以调用的地方【生产者】
PVC:用于调用,不需要关心内部实现细节【消费者】
PV 和 PVC 使得 K8S 集群具备了存储的逻辑抽象能力。使得在配置 Pod 的逻辑里可以忽略对实际后台存储
技术的配置,而把这项配置的工作交给 PV 的配置者,即集群的管理者。存储的 PV 和 PVC 的这种关系,跟
计算的 Node 和 Pod 的关系是非常类似的;PV 和 Node 是资源的提供者,根据集群的基础设施变化而变
化,由 K8s 集群管理员配置;而 PVC 和 Pod 是资源的使用者,根据业务服务的需求变化而变化,由 K8s 集
群的使用者即服务的管理员来配置。
实现流程
- PVC 绑定 PV
- 定义 PVC
- 定义 PV【数据卷定义,指定数据存储服务器的 ip、路径、容量和匹配模式】
举例
创建一个 pvc.yaml
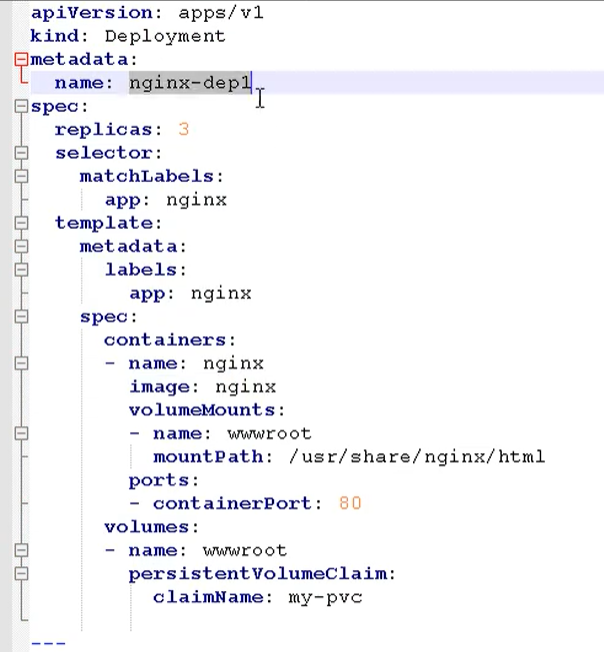
第一部分是定义一个 deployment,做一个部署
- 副本数:3
- 挂载路径
- 调用:是通过 pvc 的模式
然后定义 pvc

然后在创建一个 pv.yaml
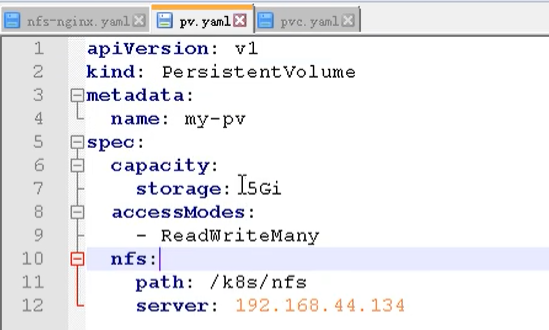
然后就可以创建 pod 了
1 | kubectl apply -f pv.yaml |
然后我们就可以通过下面命令,查看我们的 pv 和 pvc 之间的绑定关系
1 | kubectl get pv, pvc |

到这里为止,我们就完成了我们 pv 和 pvc 的绑定操作,通过之前的方式,进入 pod 中查看内容
1 | kubect exec -it nginx-dep1 bash |
然后查看 /usr/share/nginx.html

也同样能看到刚刚的内容,其实这种操作和之前我们的 nfs 是一样的,只是多了一层 pvc 绑定 pv 的操作
发布时间: 2021-01-13
最后更新: 2024-06-24
本文标题: Kubernetes学习之持久化存储
本文链接: https://blog-yilia.xiaojingge.com/posts/beb763d1.html
版权声明: 本作品采用 CC BY-NC-SA 4.0 许可协议进行许可。转载请注明出处!


