
此文章主要讲解 springcloud 中服务熔断 Hystrix(豪猪哥)的相关知识。
服务容错的核心知识
雪崩效应
- 在微服务架构中,一个请求需要调用多个服务是非常常见的。如客户端访问 A 服务,而 A 服务需要调用 B 服务,B 服务需要调用 C 服务,由于网络原因或者自身的原因,如果 B 服务或 C 服务不能及时响应,A 服务将处于阻塞状态,直到 B 服务 C 服务响应。此时如果有大量的请求涌入,容器的线程资源会被消耗完毕,导致服务瘫痪。服务和服务之间的依赖性,故障会传播,造成连锁反应,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的“雪崩”效应。
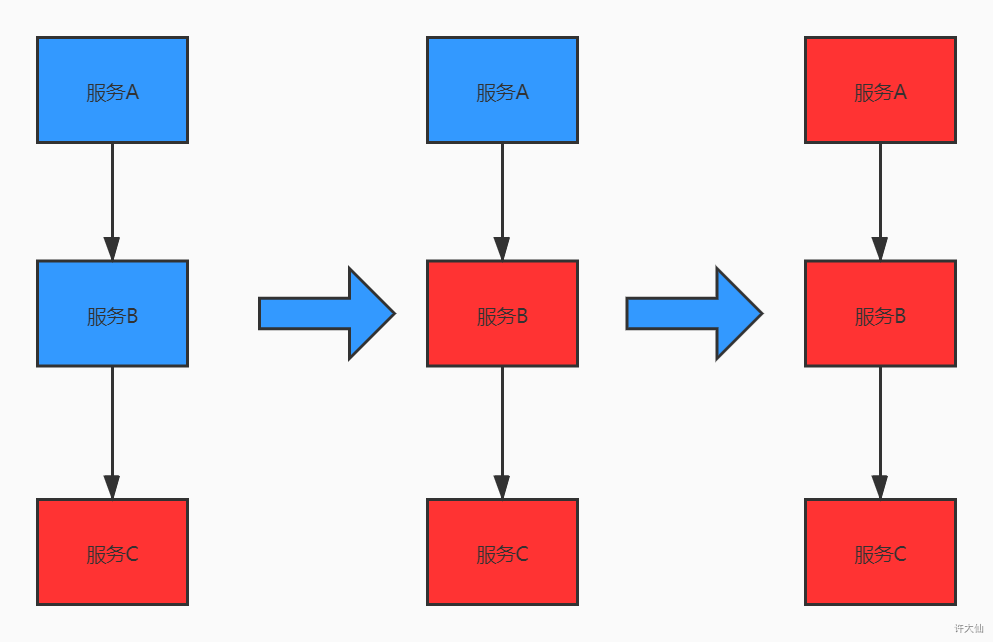
- 雪崩是系统中的蝴蝶效应,导致其发生的原因多种多样,有不合理的容量设计,或者是高并发下某一个方法响应变慢,亦或是某台机器的资源耗尽。从源头上我们无法完全杜绝雪崩源头的发生,但是雪崩的根本原因来源于服务之间的强依赖,所以我们可以提前评估,做好
熔断、隔离、限流。
服务隔离
- 顾名思义,它是指系统按照一定的原则划分若干个服务模块,各个模块之间相互独立,无强依赖性。当有故障发生时,能将问题和影响隔离在某个模块内部,而不扩散风险,不涉及到其他模块,不影响整体的系统服务。
熔断降级
- 熔断,这一概念来源于电子工程中的断路器(Circuit Breaker)。在互联网系统中,当下游服务因为当问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫熔断。
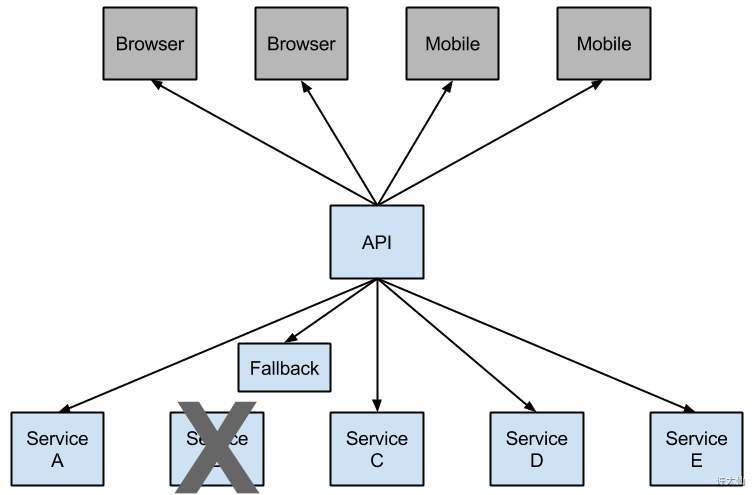
- 所谓降级,就是当某个服务熔断之后,服务将不再被调用,此时客户端可以自己准备一个本地的 fallback 回调,返回一个缺省值。也可以理解为兜底。
服务限流
- 限流可以认为是服务降级的一种,限流就是限制系统的输入和输出流量来达到保护系统的目的。一般来说,系统的吞吐量是可以被测算的,为了保证系统的稳固运行,一旦到达需要限制的阈值,就需要限制流量并采取少量措施以完成限制流量的目的。比如:推迟解决、拒绝解决或者是部分拒绝解决等等。
Hystrix
介绍
Hystrix 是由 Netflix 公司开源的一个延迟和容错库,用于隔离访问远程系统、服务或第三方库,防止级联失败,从而提升系统的可用性和容错性。Hystrix 主要通过以下的几点实现延迟和容错:
包裹请求:使用 HystrixCommand 包裹对依赖的调用逻辑,每个命令在独立线程中执行。使用了设计模式中的命令模式。跳闸机制:当某服务的错误率超过一定的阈值时,Hystrix 可以自动或者手动跳闸,停止请求该服务一段时间。资源隔离:Hystrix 为每个依赖度维护了一个小型的线程池(或者信号量)。如果该线程池已满,发往该依赖的请求就被立即拒绝,而不是排队等待,从而加速失败判定。监控:Hystrix 可以近乎实时的监控运行指标和配置的变化,例如成功、失败、超时、被拒绝的请求等等。回退机制:当请求失败、超时、被拒绝、或当断路器打开时,执行回退逻辑。回退逻辑由开发人员自行提供,例如返回一个缺省值。自我修复:断路器打开一段时间后,会自动进入“半开”状态。
概述
Github 官方地址: https://github.com/Netflix/Hystrix/wiki/How-To-Use ,可以看出已经停止更新进入维护状态了。


重要概念
服务降级
服务器忙碌或者网络拥堵时,不让客户端等待并立刻返回一个友好提示,fallback
哪些情况会触发服务降级:
程序运行异常超时服务熔断触发服务降级线程池/信号量打满也会导致服务降级
服务熔断
break

服务限流
flowlimit

可见,上面的技术不论是消费者还是提供者,根据真实环境都是可以加入配置的,一般用在消费端。
案例
首先构建一个 eureka 作为服务中心的单机版微服务架构 ,这里使用之前 cloud-eureka-server7001 模块,作为服务中心
提供者模块
新建模块
cloud-provider-hystrix-payment8001
POM 文件
1 |
|
YML 文件
1 | # 端口号 |
主启动类
1 |
|
Service
1 | package com.itjing.springcloud.service; |
Controller
1 |
|
启动测试
- 启动 注册中心 Eureka
- 启动服务提供者 cloud-provider-hystrix-payment8001
- 访问测试
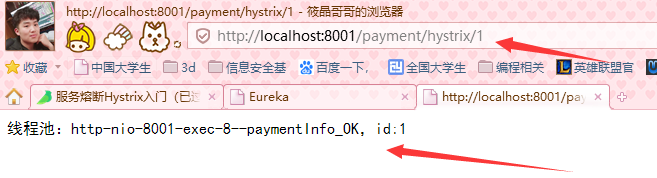
http://localhost:8001/payment/hystrix/1
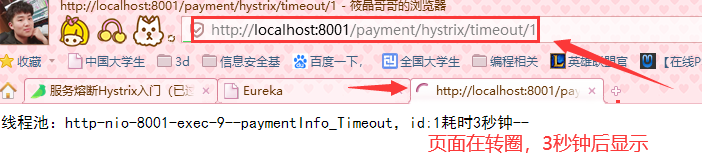
http://localhost:8001/payment/hystrix/timeout/1
模拟高并发
这里使用 JMeter 压力测试器
下载压缩包,解压,双击 /bin/ 下的 jmeter.bat 即可启动
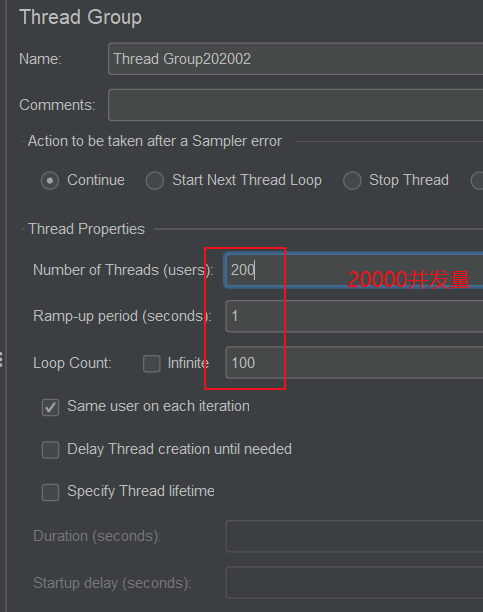
ctrl + S 保存。
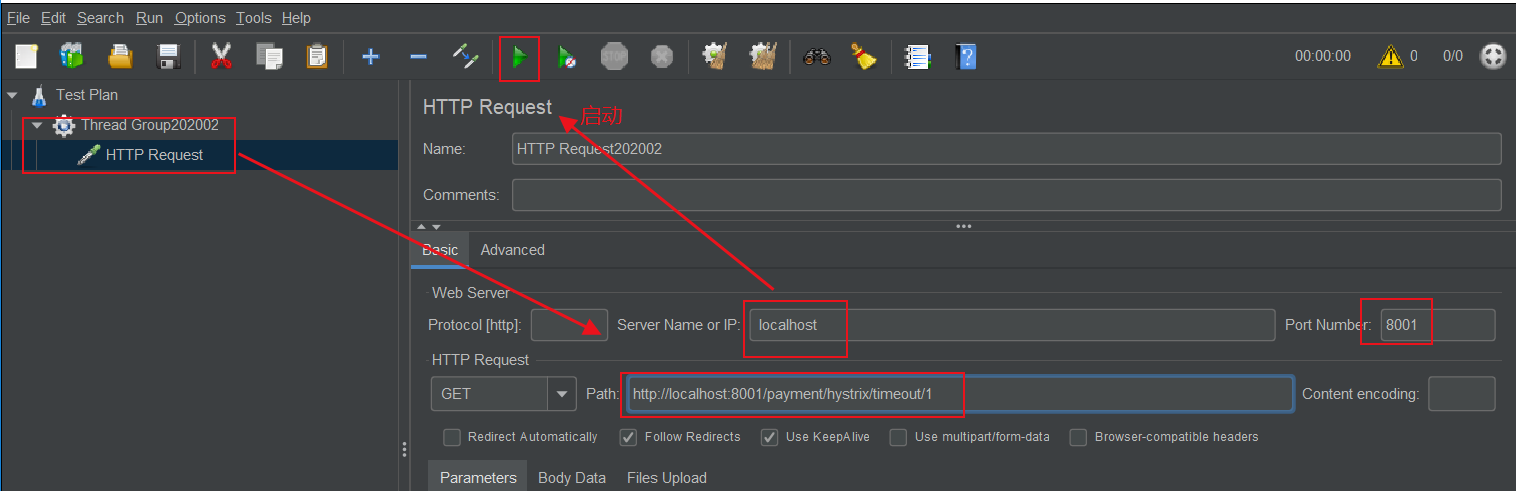
从测试可以看出,当模拟的超长请求被高并发以后,访问普通的小请求速率也会被拉低。
消费者模块
新建模块
cloud-consumer-feign-hystrix-order80,以 feign 为服务调用,eureka 为注册中心
POM 文件
1 |
|
YML 文件
1 | server: |
主启动类
1 |
|
Service 接口
1 |
|
Controller
1 |
|
测试
测试可见,当启动高并发测试时,消费者访问也会变得很慢,甚至出现超时报错。
结论
正因为有上述故障或不佳表现,才有我们的降级/容错/限流等技术诞生。
如何解决
超时导致服务器变慢(转圈)——–> 超时不再等待
出错(宕机或程序运行出错)——–> 出错要有兜底
解决思路:
对方服务(8001)超时了,调用者(80)不能一直卡死等待,必须有服务降级。
对方服务(8001)down 机了,调用者(80)不能一直卡死等待,必须有服务降级。
对方服务(8001)OK,调用者(80)自己出故障或有自我要求(自己的等待时间小于服务提供者),自己处理降级。
服务降级
一般服务降级放在客户端,即消费者端 ,但是提供者端一样能使用。
首先提供者,即 8001 先从自身找问题,设置自身调用超时的峰值,峰值内正常运行,超出峰值需要有兜底的方法处理,作服务降级fallback。
8001 服务降级
首先 对 8001 的 service 进行配置(对容易超时的方法进行配置) :
1 | /** |
主启动类添加注解: @EnableCircuitBreaker
80 服务降级
YML 文件
1 | server: |
主启动类添加注解: @EnableHystrix
然后对 80 进行服务降级:很明显 service 层是接口,所以我们对消费者,在它的 controller 层进行降级
1 | (fallbackMethod = "paymentInfo_timeoutHandler", commandProperties = { |
测试
记录下遇到的坑
controller 中超时时间配置不生效原因:
1 | #关键在于 |
Hystrix 的默认超时时间为 1 秒,我们可以通过如下的配置修改默认的超时设置:
1 | hystrix: |
然后 ribbon 的超时时间也需加上超时控制:
1 | ribbon: |
注意,消费者降级设置的超时时间和提供者的没有任何关系,就算提供者峰值是 5 秒,而消费者峰值是 3 秒,那么消费者依然报错。就是每个模块在服务降级上,都是独立的。
全局服务降级
上面的降级策略,很明显造成了代码的杂乱,提升了耦合度,而且按照这样,每个方法都需要配置一个兜底方法,很繁琐。
现在将降级处理方法(兜底方法)做一个全局的配置,设置共有的兜底方法和独享的兜底方法。
1 |
|
问题,跟业务逻辑混合,解决(解耦):
在这种方式一般是在客户端,即消费者端,首先上面在 controller 中添加的 @HystrixCommand 和 @DefaultProperties 两个注解去掉,就是保持原来的 Controller
1、YML文件配置
1 | server: |
2、编写一个类实现Service接口
1 |
|
3、修改service接口
1 |
|
新问题,这样配置如何设置超时时间?
首先要知道 下面两个 yml 配置项:
1 | =true ## 默认值 |
看懂以后,所以只需要在 yml 配置里面配置 Ribbon 的 超时时长即可。
注意:hystrix 默认自带 ribbon 包。
1 | ribbon: |
服务熔断
实际上 服务熔断 和 服务降级 没有任何关系,就像 java 和 javaScript
服务熔断,就像家里的保险丝一样
概述

实操
修改 cloud-provider-hystrix-payment8001
service 层的方法设置服务熔断
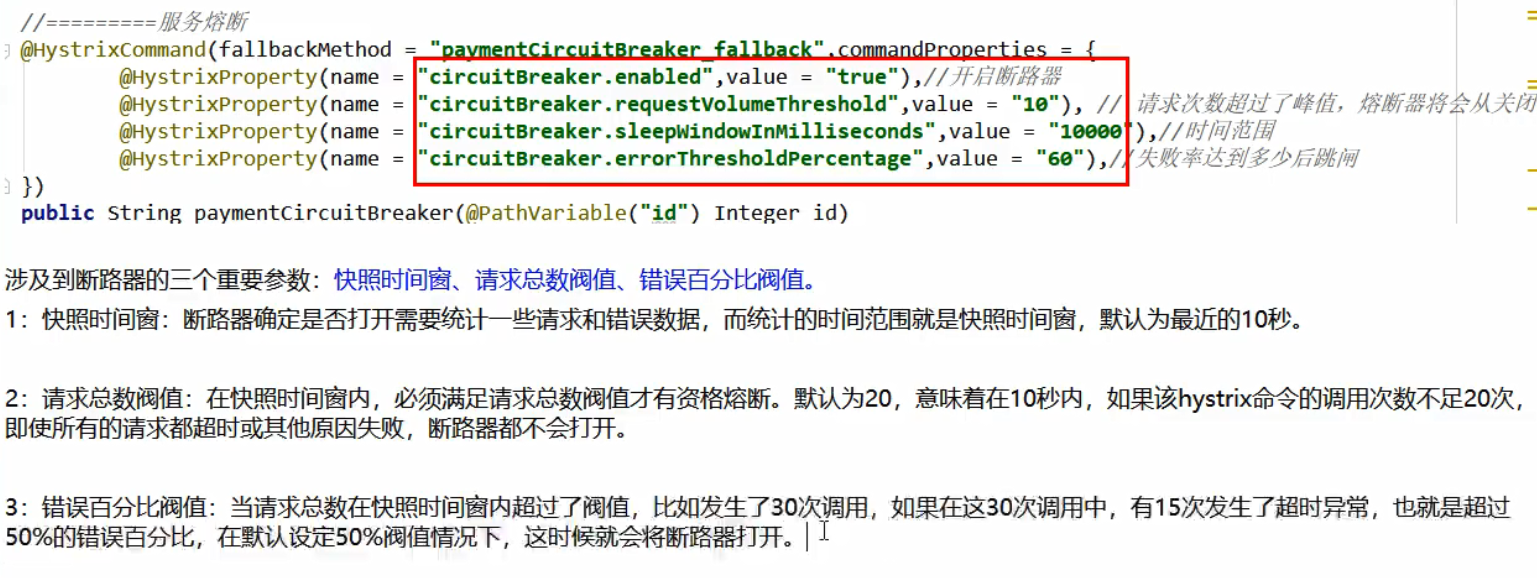
双击 shift 搜索 HystrixCommandProperties,查看相关属性
1 | //=====服务熔断 |
controller
1 | //====服务熔断 |
测试
自测:http://localhost:8001/payment/circuit/1
成功:

失败:

多次错误,然后慢慢正确,发现刚开始不满足条件,就算是正确的访问地址也不能进行正确输出,过一会才恢复正常,慢慢恢复调用链路。

关于解耦以后的全局配置说明:
例如上面提到的全局服务降级,并且是 feign+hystrix 整合,即 service 实现类的方式,如何做全局配置?
1 | hystrix: |
服务限流
后面学习 Sentinel 的时候再说。
服务监控
Hystrix DashBoard 仪表盘
概述

Hystrix 官方提供了基于图形化的 DashBoard(仪表盘)监控平台,用来直观的展示系统的运行状态。Hystrix 仪表盘可以显示每个断路器的状态。
搭建
新建模块
cloud-consumer-hystrix-dashboard9001
POM 文件
1 |
|
YML 文件
1 | server: |
主启动类
加注解: @EnableHystrixDashboard
1 |
|
服务提供者的依赖说明
所有 Provider 微服务提供者(8001/8002/8003)都需要监控依赖配置
1 | <!--监控信息完善--> |
测试
启动 9001 ,访问: http://localhost:9001/hystrix

监控实战
下面使用上面 9001 Hystrix Dashboard 项目,来监控 8001 项目 Hystrix 的实时情况:
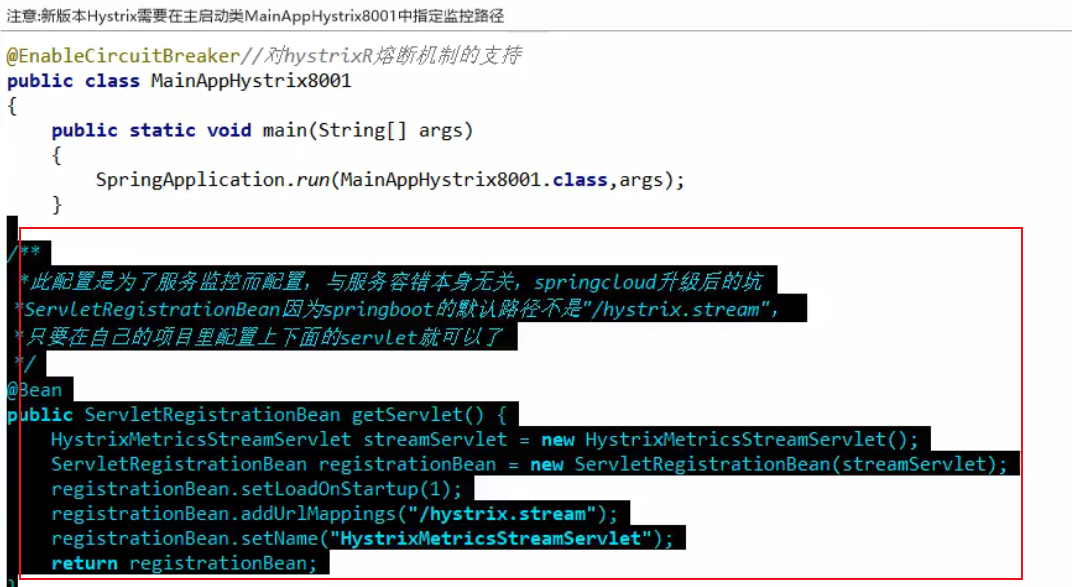
修改服务提供者
在服务提供者 cloud-provider-hystrix-payment8001 主启动类中加入以下内容:
1 |
|
监控测试
- 启动 cloud-eureka-server7001
- 启动 cloud-consumer-hystrix-dashboard9001
- 启动 cloud-provider-hystrix-payment8001
9001 监控 8001 ,输入 http://localhost:8001/hystrix.stream ,然后进去
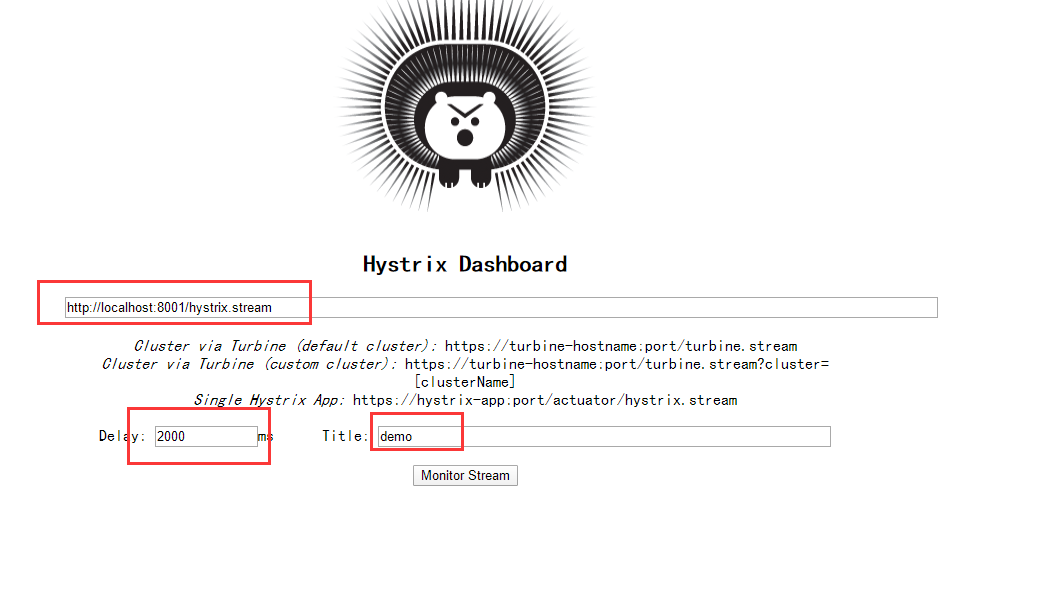
先访问测试 http://localhost:8001/payment/circuit/1

然后在仪表盘可以看到:

#
发布时间: 2021-01-18
最后更新: 2024-06-24
本文标题: SpringCloud Alibaba入门到精通(八)- 服务熔断Hystrix(已过时)
本文链接: https://blog-yilia.xiaojingge.com/posts/b7119e83.html
版权声明: 本作品采用 CC BY-NC-SA 4.0 许可协议进行许可。转载请注明出处!


