
JDK8 新特性
Lambda 表达式的介绍
使用匿名内部类存在的问题
当需要启动一个线程去完成任务的时候,通常会通过 Runnable 接口来定义任务内容,并使用 Thread 类来启动该线程。
传统写法,代码如下:
1 | package org.itjing.lambda; |
由于面向对象的语法要求,首先创建一个 Runnable 接口的匿名类对象来指定线程要执行的任务内容,再将其交给一个线程来启动。
代码分析:对于 Runnable 的匿名内部类用法,可以分析出以下几点内容:
- Thread 类需要 Runnable 接口作为参数,其中的抽象方法 run 方法是用来指定线程任务内容的核心。
- 为了指定 run 的方法体,不得不需要 Runnable 接口的实现类。
- 为了省去定义个 Runnable 实现类的麻烦,不得不使用匿名内部类。
- 必须覆盖重写 run 方法,所以方法名称,方法参数、方法返回值不得不重写一遍,且不能写错。
- 实际上,似乎只有 run 方法体才是关键所在。
体验 Lambda
Lambda 是一个匿名函数,可以理解为一段可以传递的代码。
Lambda 表达式写法,代码如下:
1 | package org.itjing.lambda; |
这段代码和使用匿名内部类的执行效果是完全一样的,可以在 JDK8 或更高的编译级别下通过。从代码的语义中可以看出:我们启动了一个线程,而线程任务的内容以一种更加简洁的形式被指定。
Lambda 的优点
简化匿名内部类的使用,语法更加简单。
Lambda 的标准格式
Lambda 的标准格式
Lambda 省去了面向对象的条条框框,Lambda 的标准格式由 3 个部分组成:
1 | (参数类型 参数名称) -> { |
格式说明:
- (参数类型 参数名称):参数列表。
- {代码体;}:方法体。
- ->:箭头,没有实际含义,起到连接的作用。
无参无返回值的 Lambda
示例,定义函数式接口:
1 | package org.itjing.lambda; |
1 | package org.itjing.lambda; |
有参数有返回值的 Lambda
示例,定义函数式接口:
1 | package org.itjing.lambda; |
1 | package org.itjing.lambda; |
总结
Lambda 表达式的标准格式:
1 | (参数列表) -> {} |
以后我们看到调用的方法其参数是函数式接口就可以考虑使用 Lambda 表达式来替代匿名内部类,但是不是所有的匿名内部类都能使用 Lambda 表达式来替代,Lambda 表达式相当于对函数式接口的抽象方法的重写。
了解 Lambda 的实现原理
1 | package org.itjing.lambda; |
1 | package org.itjing.lambda; |
我们可以看到匿名内部类会在编译后产生一个类:LambdaDemo3$1.class。
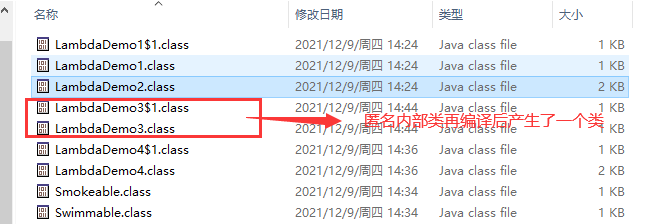
使用 XJad 反编译这个类,得到如下的代码:
1 | // Decompiled by Jad v1.5.8e2. Copyright 2001 Pavel Kouznetsov. |
我们再看 Lambda 的效果,修改代码如下:
1 | package org.itjing.lambda; |
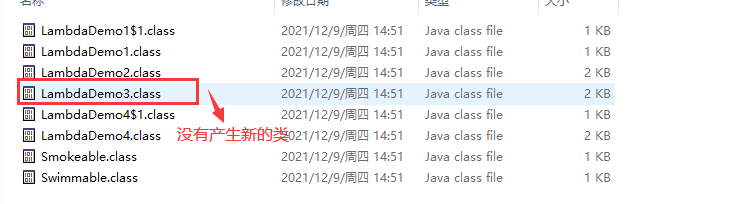
运行程序,控制台得到预期结果,但没有生成新的类,也就是说 Lambda 并没有再编译的时候产生新的类。使用 XJad 对这个类进行反编译,发现 XJad 报错。
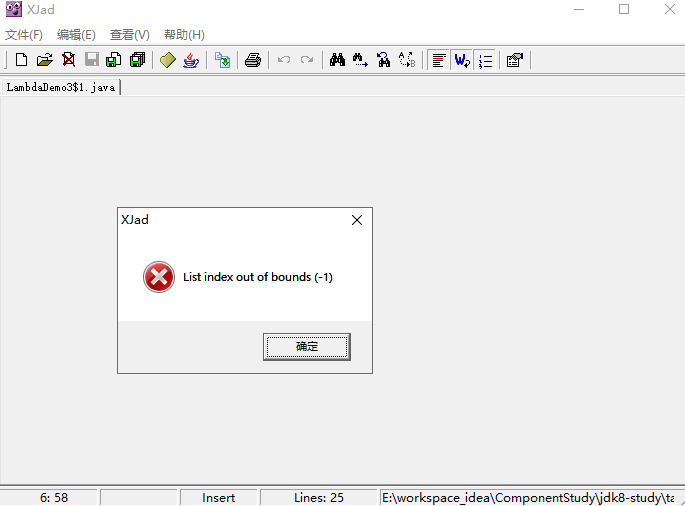
使用了 Lambda 后 XJad 反编译工具无法反编译。
我们使用 JDK 自带的一个工具:javap,对字节码进行反汇编,查看字节码指令。
1 | javap -c -p 文件名.class |
反编译的效果如下:
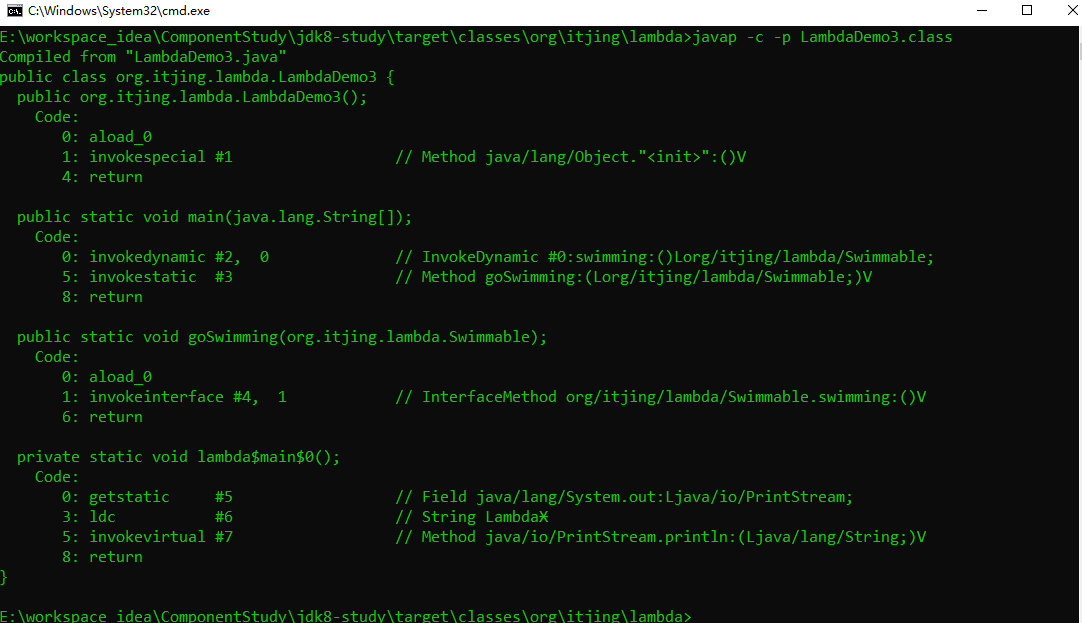
可以看到在类中多了一个私有的静态方法lambda$main$0。这个方法里面存放的是什么内容,我们可以通过断点调试来看看:
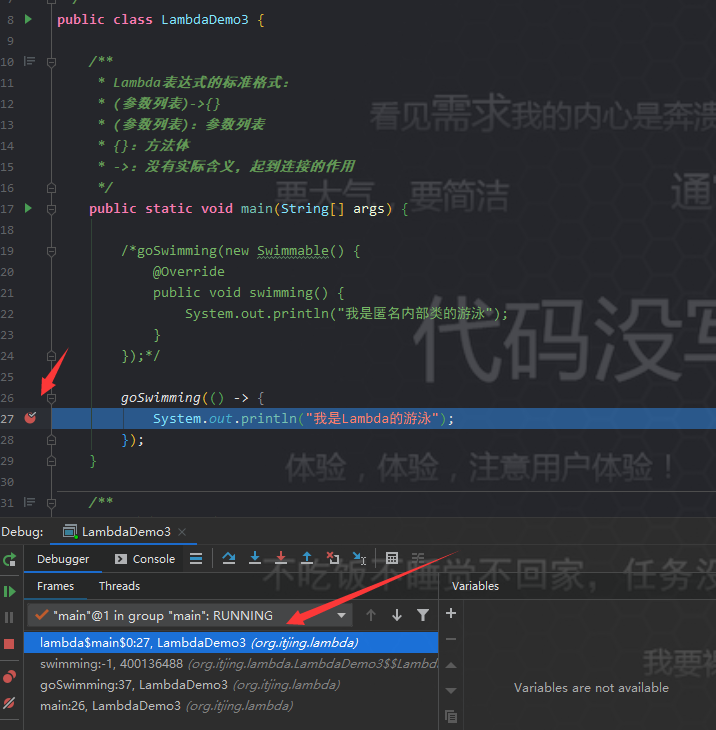
可以确认lambda$main$0里面放的就是 Lambda 中的内容,那么我们可以这么理解lambda$main$0方法:
1 | public class LambdaDemo3 { |
关于这个方法lambda$main$0的命名:以 lambda 开头,因为是在 main 函数里面使用了 Lambda 表达式,所以带有$main表示,因为是第一个,所以$0。
如果调用这个方法?其实 Lambda 在运行的时候会生成一个内部类,为了验证是否生成内部类,可以在运行的时候加上-Djdk.internal.lambda.dumpProxyClasses,加上这个参数后,运行时会将生成的内部 class 码输出到一个文件中。其命令如下:
1 | java -Djdk.internal.lambda.dumpProxyClasses 要运行的包名.类名 |
根据上面的格式,在命令行输入以下的命令:
1 | java -Djdk.internal.lambda.dumpProxyClasses org.itjing.lambda.LambdaDemo3 |

执行完毕,可以看到生成一个新的类,效果如下:
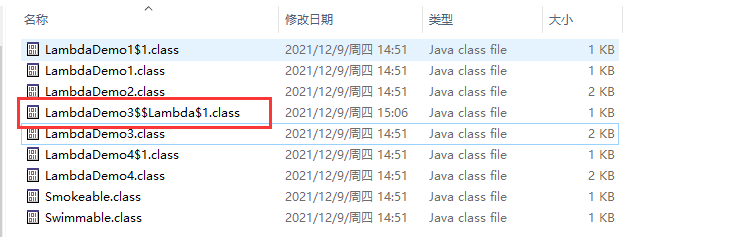
使用 XJad 反编译LambdaDemo3$$Lambda$1.class这个字节码文件,内容如下:
1 | // Decompiled by Jad v1.5.8e2. Copyright 2001 Pavel Kouznetsov. |
可以看到这个匿名内部类实现了 Swimmable 接口,并且重写了 swimming 方法,swimming 方法调用LambdaDemo3.lambda$main$0(),也就是调用 Lambda 中的内容。最后可以将 Lambda 理解为:
1 | public class LambdaDemo3 { |
Lambda 的省略格式
再 Lambda 标准格式的基础上,使用省略写法的规则是:
- 小括号内的参数类型可以省略。
- 如果小括号内有且仅有一个参数,则小括号可以省略。
- 如果大括号内有且仅有一个语句,则可以同时省略大括号、return 关键字以及语句的分号。
示例:
Lambda 的标准格式:
1 | (int a ) -> { |
Lambda 表达式省略后:
1 | a -> new Person() |
Lambda 的前提条件
Lambda 的语法非常简洁,但是 Lambda 表达式不是随随便便就能使用的,使用时需要注意以下几个条件:
- 方法的参数或局部变量类型必须为接口时才能使用 Lambda。
- 接口中有且仅有一个抽象方法(函数式接口)。
示例:
1 | package org.itjing.lambda; |
1 | package org.itjing.lambda; |
函数式接口
函数式接口在 Java 中是指有且仅有一个抽象方法的接口。
函数式接口,即适用于函数式编程场景的接口。
而 Java 中的函数式编程体现就是 Lambda,所以函数式接口就是可以适用于 Lambda 使用的接口。
只有确保接口中有且仅有一个抽象方法,Java 中的 Lambda 才能顺利的进行推导。
Java8 中专门为函数式接口引入了一个新的注解:@FunctionalInterface。
该注解用于接口的定义上。
一旦使用该注解来定义接口,编译器将会强制检查是否确实仅有一个抽象方法,否则将会报错。
不过,即使不使用该注解,只要满足函数式接口的定义,这仍然是一个函数式接口,使用起来都一样,加了注解是为了校验接口是否满足函数式接口的定义。
Lambda 和匿名内部类的对比
所需的类型不一样:
- 匿名内部类,需要的类型可以是类、抽象类、接口。
- Lambda,需要的类型必须是接口。
抽象方法数量不一样:
- 匿名内部类所需接口中的抽象方法的数量随意。
- Lambda 所需接口中的抽象方法的数量有且仅有一个。
实现原理不同:
- 匿名内部类是在编译后会形成 class 文件。
- Lambda 是在程序运行的时候动态生成 class 文件。
JDK8 接口新增的两种方法
概述
在 JDK8 以前的接口:
1 | interface 接口名{ |
JDK8 对接口进行了增强,接口还可以有默认方法和静态方法。
1 | interface 接口名{ |
####
接口引入默认方法的背景
在 JDK8 以前接口中只能有抽象方法。存在如下问题:
如果给接口中新增抽象方法,所有实现类都必须重写这个抽象方法。不利于接口的扩展。
1 | package org.itjing.inter; |
例如,JDK8 的时候,Map 接口新增了 forEach 方法:
1 | public interface Map<K,V> { |
通过 API 可以查询到 Map 接口的实现类:
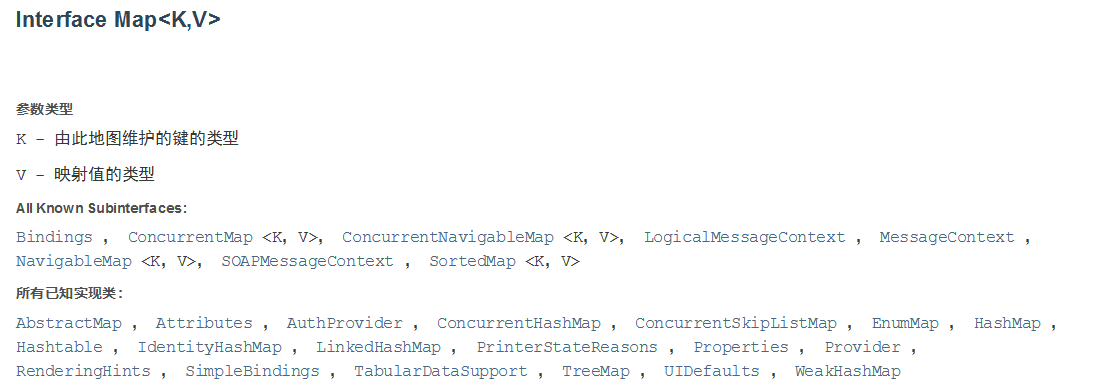
如果在 Map 接口中增加一个抽象方法,所有的实现类都需要去实现这个方法,那么工程量是巨大的。
因此,在 JDK8 为接口新增了默认方法,效果如下:
1 | public interface Map<K,V> { |
接口中的默认方法实现类不必重写,可以直接使用,实现类也可以根据需要重写,这样就方便接口的扩展。
接口默认方法的定义格式
1 | interface 接口名{ |
接口的默认方法的使用
① 实现类可以直接使用接口中的默认方法。
1 | package org.itjing.inter; |
② 实现类重写接口中的默认方法
1 | package org.itjing.inter; |
接口静态方法的定义格式
1 | interface 接口名{ |
接口静态方法的使用
直接使用接口名调用即可:接口名.静态方法名();
接口中的静态方法不能被继承,也不能被重写。
1 | package org.itjing.inter; |
接口中默认方法和静态方法的区别
- 接口中的默认方法是通过实例调用,而接口中的静态方法是通过接口名调用。
- 接口中的默认方法可以被继承,实现类可以直接使用接口中的默认方法,也可以重写接口中的默认方法。
- 接口中的默认方法可以被继承,实现类可以直接使用接口中的默认方法,也可以重写接口中的默认方法。
常用内置函数式接口
内置函数式接口的由来
我们知道使用 Lambda 表达式的前提是需要有函数式接口。
而 Lambda 使用时不关心接口名、抽象方法名,只关系抽象方法的参数列表和返回值类型。
因此为了让我们使用 Lambda 方便,JDK 提供了大量常用的函数式接口。
常用的函数式接口介绍
它们主要在java.util.function包中。
下面是最常用的几个接口:
① Supplier 接口:供给型接口。
1 |
|
② Consumer 接口:消费型接口。
1 |
|
③ Function:函数型接口。
1 |
|
④ Predicate:断言型接口。
1 |
|
Supplier 接口
java.util.function.Supplier<T>接口,它意味着“供给”,对应的 Lambda 表达式需要对外提供一个符合泛型类型的对象数据。
1 |
|
供给型接口,通过 Supplier 接口中的 get 方法可以得到一个值,无参有返回值的接口。
示例:使用 Lambda 表达式返回数组元素的最大值。
1 | package org.itjing.lambda; |
Consumer 接口
java.util.function.Consumer<T>接口正好相反,它不是生产一个数据,而是消费一个数据,其数据类型由泛型参数决定。
1 |
|
示例:使用 Lambda 表达式将一个字符串转成大写和小写字符串。
1 | package org.itjing.lambda; |
示例:使用 Lambda 表达式将一个字符串先转成小写然后在转成大写。
1 | package org.itjing.lambda; |
Function 接口
java.util.function.Function<T, R>接口用来根据一个类型的数据得到另一个类型的数据,前者称为前置条件,后者称为后置条件。有参数有返回值。
1 |
|
示例:
1 | package org.itjing.lambda; |
Predicate 接口
有时我们需要对某种类型的数据进行判断,从而得到一个 boolean 值的结果,这时可以使用java.util.function.Predicate<T>接口。
1 |
|
示例:使用 Lambda 判断一个名称,如果名称超过 3 个字就认为是很长的名称。
1 | package org.itjing.lambda; |
示例:
1 | package org.itjing.lambda; |
方法引用
介绍方法引用
示例:使用 Lambda 表达式求一个数组的和
1 | package org.itjing.lambda; |
注意其中的双冒号::写法,这被称为”方法引用”,是一种新的语法。
方法引用的前提:方法引用所引用的方法的参数列表必须要和函数式接口中抽象方法的参数列表相同(完全一致)。
方法引用所引用的方法的的返回值类型必须要和函数式接口中抽象方法的返回值类型相同(完全一致)。
方法引用的格式
符号表示:
::。符号说明:双冒号为方法引用运算符,而它所在的表达式被称为
方法引用。应用场景:如果 Lambda 所要实现的方案,已经有了其他方法存在相同方法,那么就可以使用方法引用。
常用的引用方式
方法引用在 JDK8 中使用方式非常灵活,有以下几种形式。
- 实例名::成员方法名。
- 类名::静态方法名。
- 类名::方法名。
- 类名::new。
- 数据类型[]::new。
实例名::成员方法名
如果一个类中已经存在了一个成员方法,则可以通过实例名引用成员方法。
1 | package org.itjing.lambda; |
类名::静态方法名
由于在 java.lang.System 类中已经存在了许多静态方法,比如 currentTimeMillis()方法,所以当我们需要通过 Lambda 来调用这些静态方法的时候,可以使用类名::静态方法名。
1 | package org.itjing.lambda; |
类名::方法名
Java 面向对象中,类名只能调用静态方法,类名引用实例方法是有前提的。
实际上是拿入参数作为调用方法的参数。
1 | package org.itjing.lambda; |
类名::new
由于构造器的名称和类名完全一样,所以构造器引用使用类名::new的格式表示。
1 | package org.itjing.lambda; |
数据类型[]::new
数组也是 Object 的子类,所以具有同样的构造器。
1 | package org.itjing.lambda; |
总结
方法引用是对 Lambda 表达式符合特定情况下的一种缩写,它使得我们的 Lambda 表达式更加的精简,也可以理解为 Lambda 表达式的缩写形式,不过要注意的是方法引用只能引用已经存在的方法。
Stream API
集合处理数据的弊端
当我们需要对集合中的元素进行操作的时候,除了必需的添加、删除、获取外,最典型的就是集合的遍历。
我们来体验集合操作数据的弊端,需求如下:
一个 ArrayList 集合中存储有以下数据:张无忌、周芷若、赵敏、张强、张三丰
需求:① 拿到所有姓张的
② 拿到名字长度为 3 个字的
③ 打印这些数据
代码如下:
1 | package org.itjing.stream; |
循环遍历的弊端:
上面的代码中包含三个循环,每一个作用不同:
- 首先筛选所有姓张的人;
- 然后筛选名字中有三个字的人;
- 最后对结果进行打印输出。
每当我们需要对集合中的元素进行操作的时候,总是需要进行循环、循环、再循环,这样太麻烦了。
Stream 的优雅的写法:
1 | package org.itjing.stream; |
Stream 流式思想概述
Stream 流式思想类似于工厂车间的”生产流水线”,Stream 流不是一种数据结构,不保存数据,而是对数据进行加工处理。
Stream 可以看作是流水线上的一个工序。
在流水线上,通过多个工序让一个原材料加工成一个商品。
Stream API 能让我们快速完成许多重复的操作,如筛选,切片、映射、查找、去除重复、统计、匹配和归约。
获取 Stream 流的方式
① java.util.Collection 接口中加入了 default 方法 stream()用来获取流,所以其所有的实现类均可获取 Stream 流。
1 | public interface Collection<E> extends Iterable<E> { |
示例:
1 | List<Integer> list = Arrays.asList(1, 2, 3); |
② Stream 接口的静态方法 of 可以获取数组对应的 Stream 流。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
示例:
1 | Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5); |
③ java.util.Arrays 的 stream()方法获取数组对应的 Stream 流。
1 | public class Arrays { |
示例:
1 | Stream<Integer> stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5}); |
Stream 常用方法
Stream 流模型的操作非常丰富,这里介绍一些常用的 API。
| 方法名 | 方法作用 | 返回值类型 | 方法种类 |
|---|---|---|---|
| count | 统计个数 | long | 终结 |
| forEach | 逐一处理 | void | 终结 |
| filter | 过滤 | Stream | 函数拼接 |
| limit | 取前几个 | Stream | 函数拼接 |
| skip | 跳过前几个 | Stream | 函数拼接 |
| map | 映射 | Stream | 函数拼接 |
| concat | 组合 | Stream | 函数拼接 |
终结方法:返回值类型不是 Stream 类型的方法,不再支持链式调用。
非终结方法:返回值类型是 Stream 类型的方式,支持链式调用。
Stream 注意事项
- Stream 只能操作一次
- Stream 方法返回的是新的流。
- Stream 不调用终结方法,中间的操作不会执行。
Stream 流的 forEach 方法
Stream中的forEach方法用来遍历流中的数据,该方法接收一个 Consumer 接口函数,会将每一个流元素交给该函数进行处理
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
Map中的forEach方法用来遍历 Map 中的每个 Map.Entry 类型的元素,该方法接受一个 BiConsumer 接口函数,会将 Map.Entry 类型元素的 key 和 value 交给该函数进行处理。
1 | public interface Map<K,V> { |
示例:
1 | List<String> list = new ArrayList<>(); |
1 | Map<String,Object> map = new HashMap<>(); |
Stream 流的 count 方法
Stream 流提供 count 方法来统计其中的元素个数:
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
示例:
1 | Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 0); |
Stream 流的 filter 方法
Stream 流中的 filter 方法用于过滤数据,返回符合条件的数据。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
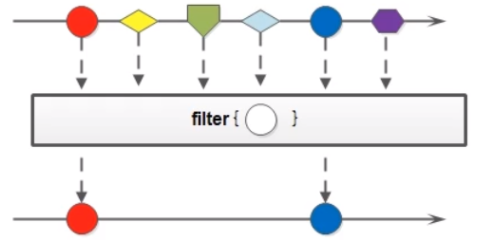
示例:
1 | Stream<String> stream = Stream.of("张三", "李四", "王五", "赵六", "贾七", "沈八"); |
Stream 流中的 limit 方法
Stream 流中的 limit 方法可以对流进行截取,只取前 n 个。
参数是一个 long 类型,如果集合当前长度大于参数则进行截取,否则不进行任何操作。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
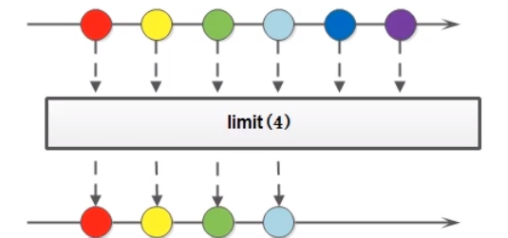
示例:
1 | Stream<String> stream = Stream.of("张三", "李四", "王五", "赵六", "贾七", "沈八"); |
Stream 流中的 skip 方法
如果希望跳过前 n 个元素,可以使用 skip 方法获取一个截取之后的新流:
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
如果流当前的长度大于 n,则跳过前 n 个;否则将会得到一个长度为 0 的空流。
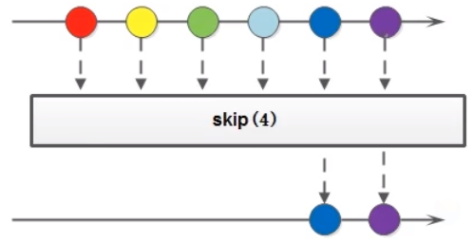
示例:
1 | Stream<String> stream = Stream.of("张三", "李四", "王五", "赵六", "贾七", "沈八"); |
Stream 流中的 map 方法
如果需要将流中的元素映射到另一个流中,可以使用 map 方法。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
该接口需要一个 Function 函数式接口参数,可以将当前流中的 T 类型转换为另一种 R 类型的流。
使用场景:
- 转换流中的数据格式。
- 提取流的对象属性
示例:
1 | Stream<String> stream = Stream.of("1", "2", "3", "4", "5", "6"); |
Stream 流中的 flatMap 方法
Stream 流中的 flatMap 方法是一个维度升降的方法。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
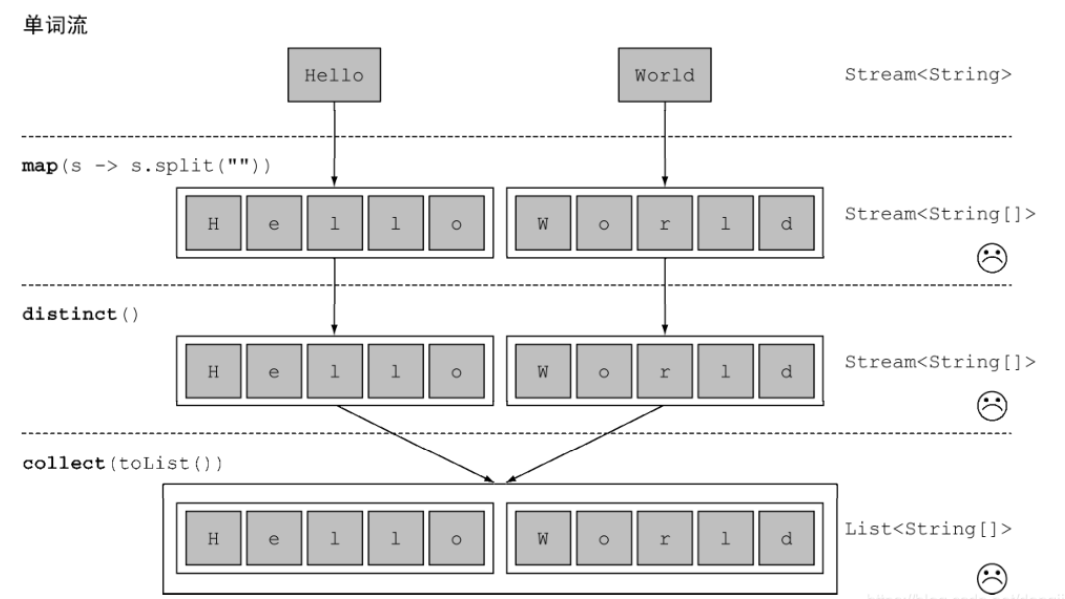
比如说:给定单词列表 [“Hello”,“World”] ,要返回列表 [“H”,“e”,“l”, “o”,“W”,“r”,“d”] 。
如果我们使用如下方式:
1 | package org.itjing.stream; |
结果:
转变类型为:Stream<String> -> Stream<String[]>-> Stream<String[]>-> List<String[]>,当前维度从一维变成二维,map本身不能降维度,执行如下:
可以通过 idea 调试查看具体过程:
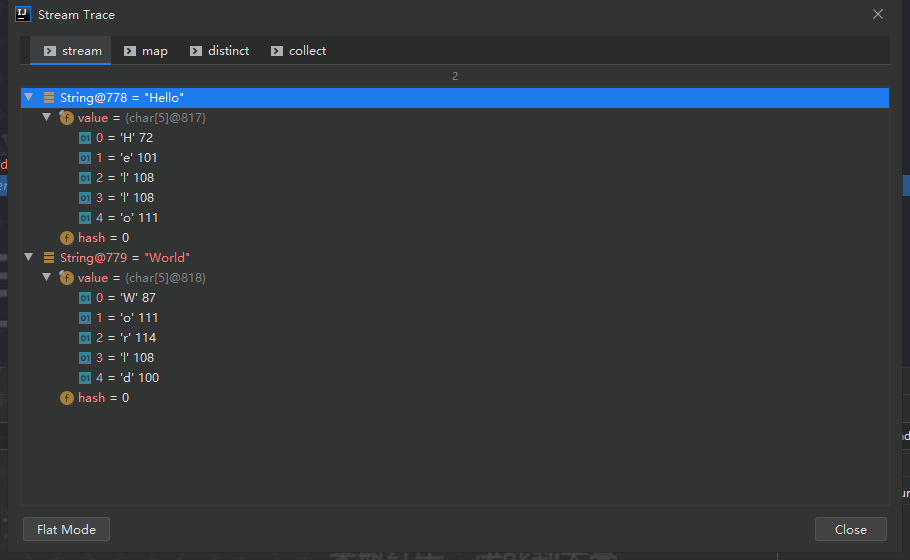
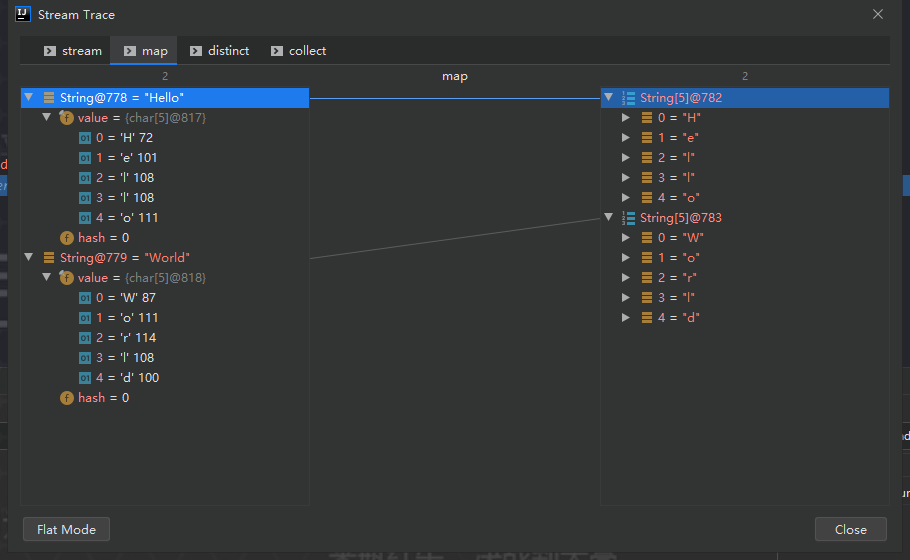
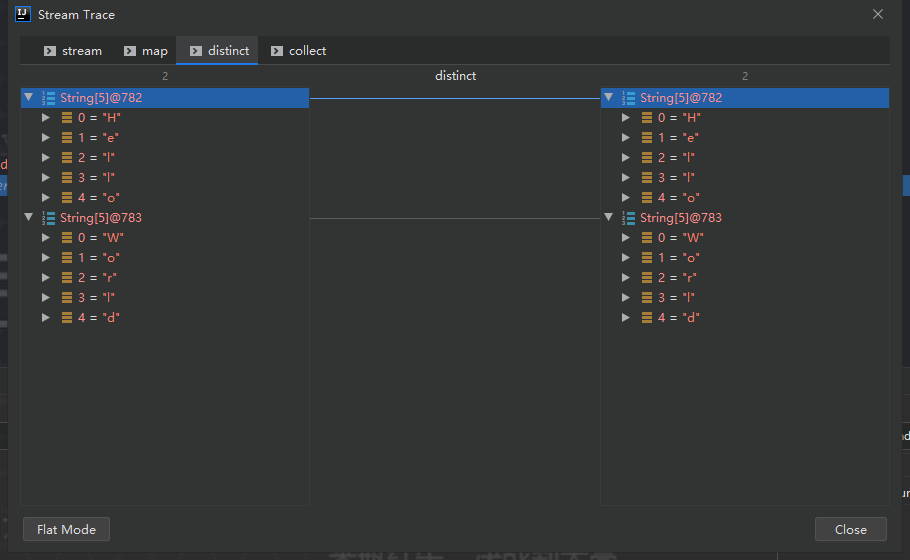
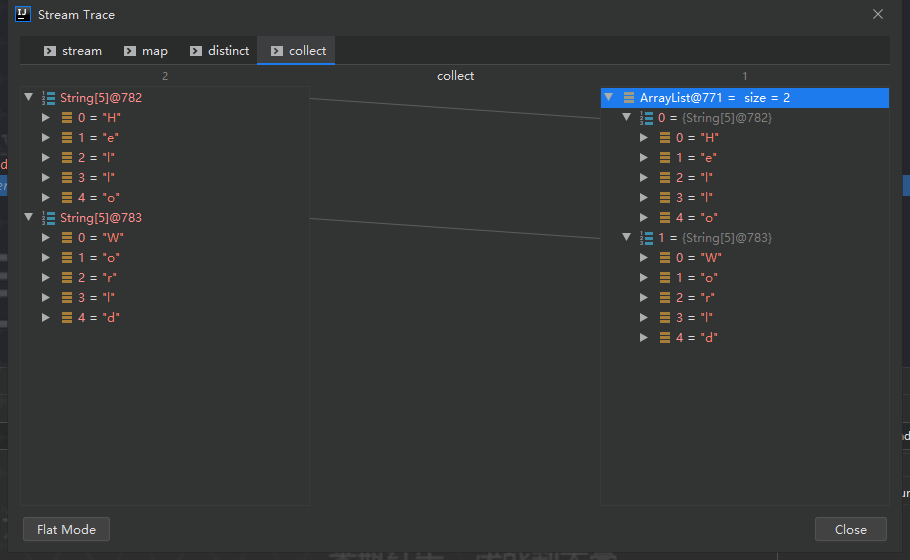
引入 flatMap 方法
1 | package org.itjing.stream; |
这里是从二维降为一维,逻辑如下:
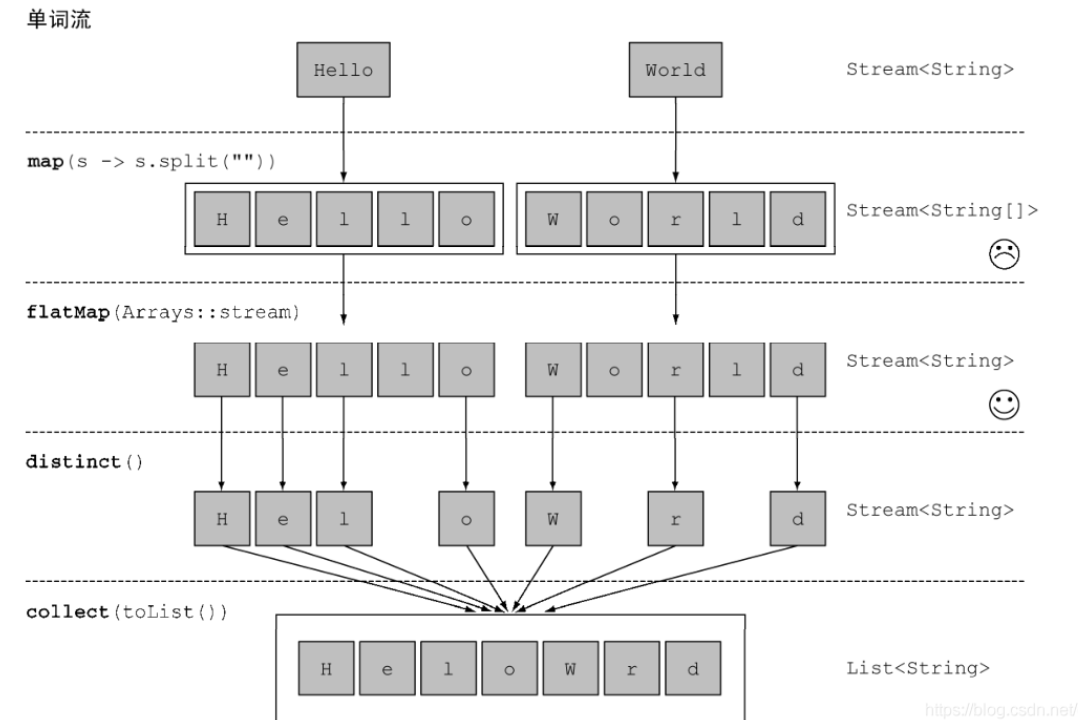
从 IDEA 编译器的提醒中,也可以看出降维了:
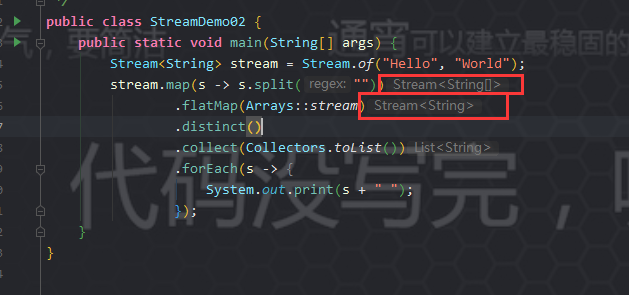
flatMap 升维
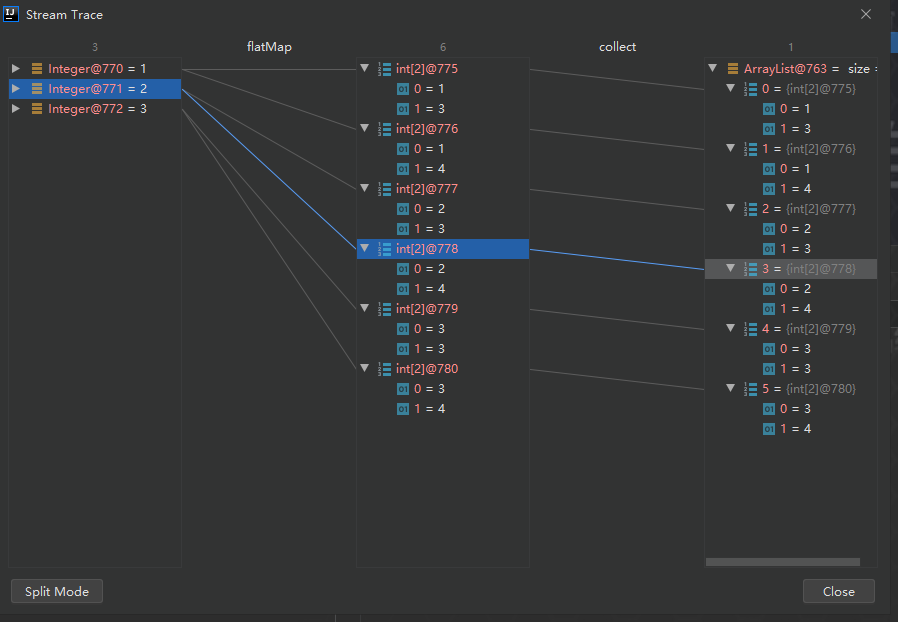
给定两个数字列表,如何返回所有的数对呢?
例如,给定列表[1, 2, 3]和列表[3, 4],应该返回[(1, 3), (1, 4), (2, 3), (2, 4), (3, 3), (3, 4)]。
1 | package org.itjing.stream; |
测试结果:
1 | [1, 3] |
这里是从一维升为二维,逻辑如下:
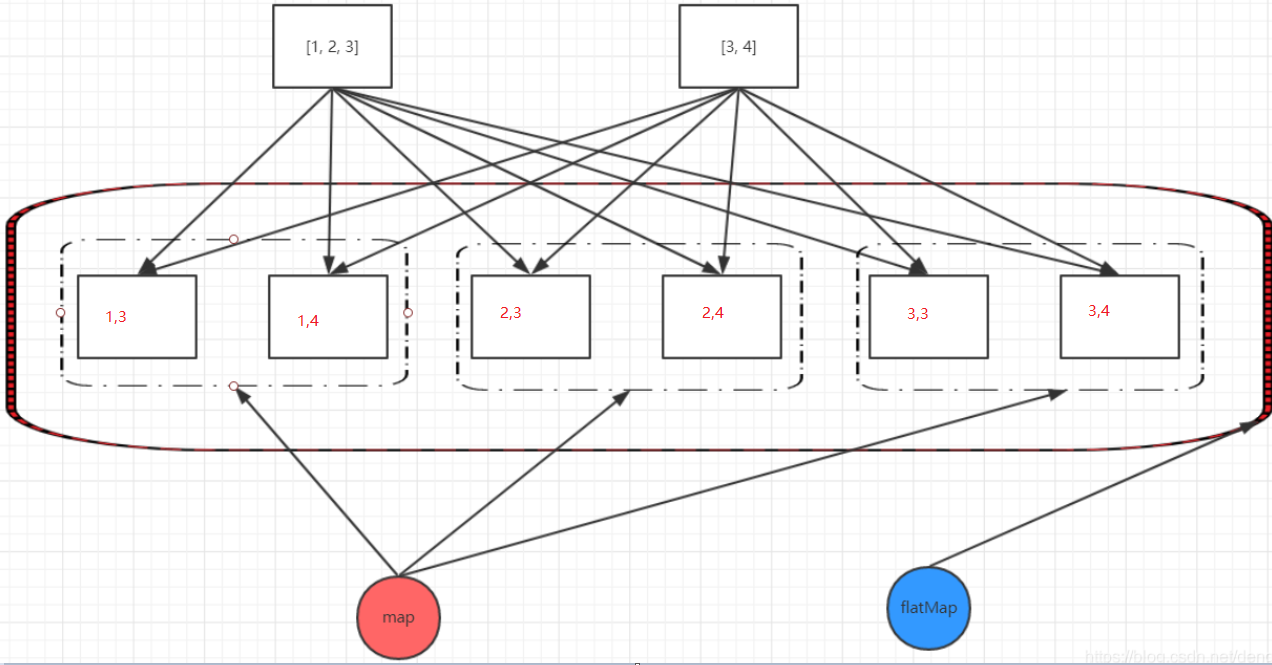
总结:flatMap将map结果归类,从而达到升降维目的。
Stream 流中的 sorted 方法
如果需要将数据排序,可以使用 sorted 方法。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
示例:
1 | List<Integer> list = new ArrayList<>(); |
Stream 流中的 distinct 方法
如果需要去除重复数据,可以使用 distinct 方法。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
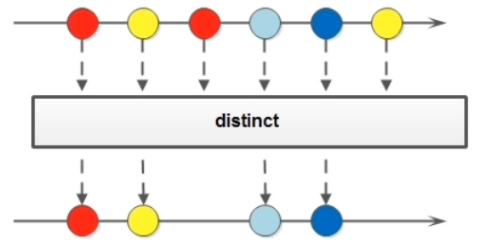
示例:
1 | List<Integer> list = new ArrayList<>(); |
Stream 流中的 match 方法
如果需要判断数据是否匹配指定的条件,可以使用 match 相关方法。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
示例:
1 | List<Integer> list = new ArrayList<>(); |
Stream 流中的 find 方法
如果需要找到某些数据,可以使用 find 相关方法。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
示例:
1 | List<String> lst1 = Arrays.asList("Jhonny", "David", "Jack", "Duke", "Jill","Dany","Julia","Jenish","Divya"); |
Stream 流中的 max 和 min 方法
如果需要获取最大值和最小值,可以使用 max 和 min 方法。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
示例:
1 | List<Integer> list = new ArrayList<>(); |
Stream 流中的 reduce 方法
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |

方式一:
1 | T reduce(T identity, BinaryOperator<T> accumulator); |
提供一个跟 Stream 中数据同类型的初始值 identity,通过累加器 accumulator 迭代计算 Stream 中的数据,得到一个跟 Stream 中数据相同类型的最终结果
示例:
1 | Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5); |
方式二:
1 | Optional<T> reduce(BinaryOperator<T> accumulator); |
函数式接口BinaryOperator,继承于BiFunction,Bifunction中有一个apply方法,接收两个参数,返回一个结果,并且这些类型都是相同的
1 |
|
1 |
|
也就是说,reduce(BinaryOperator<T> accumulator)方法需要一个函数式接口参数,该函数式接口需要两个参数,返回一个结果(reduce 中返回的结果会作为下次累加器计算的第一个参数),也就是累加器。
示例:
1 | Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5); |
方式三:
1 | <U> U reduce(U identity, |
第一个参数:返回实例 u,传递你要返回的 U 类型对象的初始化实例 u;
第二个参数:累加器 accumulator,可以使用 lambda 表达式,声明你在 u 上累加你的数据来源 t 的逻辑,例如(u,t)->u.sum(t),此时 lambda 表达式的行参列表是返回实例 u 和遍历的集合元素 t,函数体是在 u 上累加 t;
第三个参数:参数组合器 combiner,接受 lambda 表达式。
首先看一下BiFunction的三个泛型类型分别是U、 ? super T、U。
参考BiFunction函数式接口 apply 方法定义可以知道,累加器通过类型为 U 和 ? super T 的两个输入值计算得到一个 U 类型的结果返回。
也就是说这种 reduce 方法,提供一个不同于Stream中数据类型的初始值,通过累加器规则迭代计算 Stream 中的数据,最终得到一个同初始值同类型的结果。
再看一下 BinaryOperator 的泛型是 U,函数式接口BinaryOperator,继承于BiFunction,Bifunction中有一个apply方法,接收两个参数,返回一个结果,并且这些类型都是相同的。
即参数类型都是U,返回结果类型也是U。
示例:
1 | ArrayList<Integer> accResult_ = Stream.of(1, 2, 3, 4) |
示例代码中,第一个参数是ArrayList,在第二个函数参数中打印了“BiFunction”,而在第三个参数接口中打印了函数接口中打印了”BinaryOperator“。
看下面的打印结果,只打印了“BiFunction”,而没有打印”BinaryOperator“,也就是说第三个函数参数并没有执行。分析参数时我们知道了该变形可以返回任意类型的数据。
这是因为 reduce 的第三个参数是在使用 parallelStream 的 reduce 操作时,合并各个流结果的,本例中使用的是 stream,所以第三个参数是不起作用的。
输出结果:
1 | item: 1 |
对于第三个函数参数,为什么没有执行,而且其参数必须为返回的数据类型?
这是因为Stream是支持并发操作的,为了避免竞争,对于reduce线程都会有独立的result,combiner的作用在于合并每个线程的result得到最终结果。这也说明了了第三个函数参数的数据类型必须为返回数据类型了。
另外需要注意:因为第三个参数用来处理并发操作,如何处理数据的重复性,应多做考虑,否则会出现重复数据!
Stream 流中的 mapToInt 方法
如果需要将Stream<Integer>中的 Integer 类型转成 int 类型,可以使用 mapToInt 方法。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
示例:
1 | // Integer占用的内存比int多,在Stream流操作中会自动装箱和拆箱 |
Stream 流中的 concat 方法
如果有两个流,希望合并成一个流,那么就可以使用 Stream 接口中的静态方法 concat。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
示例:
1 | Stream<Integer> stream1 = Stream.of(1, 2, 3); |
收集 Stream 结果
Stream 流中的结果保存到集合中
- Stream 流提供 collect 方法,其参数需要一个
java.util.stream.Collector<T, A, R>接口对象来指定收集到那种集合中。 java.util.stream.Collectors类提供一些方法,可以作为 Collector 接口的实例。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
示例:
1 | Stream<Integer> stream1 = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 0); |
1 | package org.itjing.stream; |
Stream 流中的结果保存到数组中
Stream 流提供 toArray 方法,以便将 Stream 流中的结果保存到数组中。
1 | public interface Stream<T> extends BaseStream<T, Stream<T>> { |
示例:
1 | // Stream流中的数据转换成Object数组 |
对流中数据进行聚合计算
当我们使用 Stream 流处理数据的时候,可以像数据库的聚合函数一样对某个字段进行操作。
比如获取最大值、获取最小值、求和、平均值、统计数量。
示例:
1 | // 注意:Stream流一旦调用终止方法,就不可以再操作。 |
对流中的数据进行分组
当我们使用 Stream 流处理数据后,可以根据某个属性进行数据分组。
示例:
1 | package org.itjing.stream; |
1 | Stream<Person> stream = Stream.of( |
对流中的数据进行多级分组
还可以对流中的数据进行多级分组。
示例:
1 | Stream<Person> stream = Stream.of( |
结果:
1 | sex = 女 |
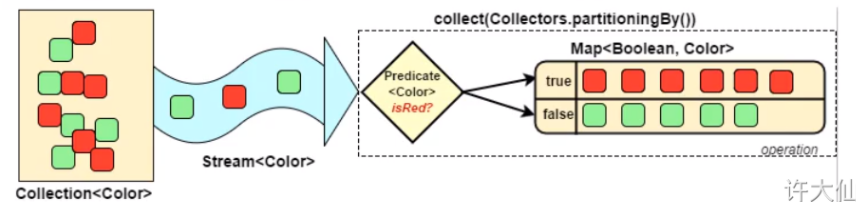
对流中的数据进行分区
Collectors 的 partitioningBy 方法会根据值是否为 true,把流中的数据分为两个部分,一个是 true 的部分,一个是 false 的部分。
示例:
1 | Stream<Person> stream = Stream.of( |
对流中的数据进行拼接
Collectors 的 joining 方法会根据指定的连接符,将所有元素连接成一个字符串。
示例:
1 | Stream<Person> stream = Stream.of( |
结果:
1 | str = (#^.^#)鞠婧祎><赵丽颖><杨颖><迪丽热巴><柳岩^_^ |
并行的 Stream 流
了解串行的 Stream 流
目前使用的 Stream 流是串行的,就是在一个线程上执行。
1 | Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 0); |
获取并行的 Stream 流的两种方式
直接获取并行的 Stream 流。
1 | List<String> list = new ArrayList<>(); |
将串行流转成并行流。
1 | List<String> list = new ArrayList<>(); |
Optional 类的使用
以前对 null 的处理
1 | String username = null; |
Optional 类的介绍
Optional 是一个没有子类的工具类,Optional 是一个可以为 null 的容器对象。
它的作用就是为了解决避免 NULL 检查,防止 NullPointerException。
Optional 类的创建方式:
1 | // 创建一个Optional实例 |
1 | // 创建一个空的Optional实例 |
1 | // 如果value不为null,则创建Optional实例,否则创建空的Optional实例 |
Optional 类的常用方法:
1 | // 判断是否包含值,如果包含值返回true,否则返回false |
1 | // 如果Optional有值则将其抛出NoSuchElementException异常 |
1 | // 如果存在包含值,返回包含值,否则返回参数other |
1 | // 如果存在包含值,返回包含值,否则返回other获取的值 |
1 | // 如果存在包含值,对其处理,并返回处理后的Optional,否则返回Optional.empty() |
1 | // 传一个断言函数,以此过滤Optional实例 |
Optional 类的基本使用
1 | package org.itjing.optional; |
Optional 类的高级使用
1 | package org.itjing.optional; |
JDK8 新的时间和日期 API
旧版日期时间 API 存在的问题
- 设计很差,在 java.util 和 java.sql 的包中都有日期类,java.util.Date 同时包含日期和时间,而 java.sql.Date 仅包含日期。此外用于格式化和解析的类在 java.text 包中定义。
- 非线程安全:java.util.Date 是非线程安全的,所有的日期类都是可变的,这是 Java 日期类最大的问题之一。
- 时区处理麻烦:日期类并不提供国际化,没有时区支持,因此引入了 java.util.Calendar 和 java.util.TimeZone 类,但它们同样存在上述所有问题。
新日期时间 API 介绍
JDK8 中增加了一套全新的日期时间 API,这套 API 设计合理,是线程安全的。
新的日期和时间 API 位于 java.time 包中,下面是一些关键类。
- LocalDate:表示日期,包含年、月、日,格式为 2021-12-12。
- LocalTIme:表示时间,包含时、分、秒,格式为 14:28:40.426000700。
- LocalDateTime:表示日期时间,包含年、月、日、时、分、秒,格式为 2020-09-08T14:29:37.546506。
- DateTimeFormatter:日期时间格式化类。
- Instant:时间戳,表示一个特定的时间瞬间。
- Duration:用于计算 2 个时间(LocalTime,Instant 等)的距离。
- Period:用于计算 2 个日期(LocalDate)的距离。
- ZoneDateTime:包含时区的时间。
Java 中使用的历法是 ISO 8601 日历系统,它是世界民用历法,也就是我们所说的公历。平年有 365 天,闰年有 366 天。此外 Java8 还提供了 4 条其他历法,分别是:
- ThaiBuddhistDate:泰国佛教历法。
- MinguoDate:中华民国历法。
- JapaneseDate:日本历法。
- HijrahDate:伊斯兰历法。
JDK8 的日期和时间类
LocalDate、LocalTime、LocalDateTime 类的实例是不可变的对象,分别表示 ISO 8601 日历系统的日期、时间、日期和时间。
它们提供了简单的日期或时间,并不包含当前的时间信息,也不包含和时区相关的信息。
示例:
1 | package org.itjing.time; |
JDK8 的时间格式化和解析
通过java.time.format.DateTimeFormatter类可以进行日期时间解析和格式化。
示例:
1 | package org.itjing.time; |
JDK8 的 Instant 类
Instant 时间戳/时间线,内部保存了从 1970 年 1 月 1 日 00:00:00 以来的秒和纳秒。
示例:
1 |
|
JDK8 的计算日期时间差类
Duration:用于计算 2 个时间(LocalTime,Instant 等)的距离。
Period:用于计算 2 个日期(LocalDate)的距离。
示例:
1 |
|
JDK8 的时间校正器
有时我们可能需要获取例如:将日期调整到下一个月的第一天等操作。可以通过时间校正器来进行。
TemporalAdjuster:时间校正器。
TemporalAdjusters:该类通过静态方法提供了大量的常用 TemporalAdjuster 的实现。
示例:
1 |
|
JDK8 设置日期时间的时区
JDK8 中加入了对时区的支持,LocalDate、LocalTime、LocalDateTIme 是不带时区的,带时区的日期时间类分别是 ZonedDate、ZonedTime、ZonedDateTime。
其中每个时区都对应的 ID,ID 的格式是“区域/城市”,比如:Asia/Shanghai 等。
ZoneId:该类中包含了所有的时区信息。
示例:
1 |
|
待续!!!!
发布时间: 2021-12-09
最后更新: 2024-06-24
本文标题: JDK8新特性
本文链接: https://blog-yilia.xiaojingge.com/posts/bcab918b.html
版权声明: 本作品采用 CC BY-NC-SA 4.0 许可协议进行许可。转载请注明出处!


